Introduction to the Fine-Tuning Scheduler¶
The FinetuningScheduler callback accelerates and enhances
foundation model experimentation with flexible fine-tuning schedules. Training with the
FinetuningScheduler (FTS) callback is simple and confers a host of benefits:
it dramatically increases fine-tuning flexibility
expedites and facilitates exploration of model tuning dynamics
enables marginal performance improvements of fine-tuned models
Note
If you’re exploring using the FinetuningScheduler, this is a great place
to start!
You may also find the notebook-based tutorial
useful and for those using the LightningCLI, there is a
CLI-based example at the bottom of this introduction.
Setup¶
Starting with version 2.10, uv is the preferred installation approach for Fine-Tuning Scheduler.
# Install uv if you haven't already (one-time setup)
curl -LsSf https://astral.sh/uv/install.sh | sh
# Install Fine-Tuning Scheduler
uv pip install finetuning-scheduler
Additional installation options (from source etc.) are discussed under “Additional installation options” in the README
Motivation¶
Fundamentally, the FinetuningScheduler callback enables
multi-phase, scheduled fine-tuning of foundation models. Gradual unfreezing (i.e. thawing) can help maximize
foundation model knowledge retention while allowing (typically upper layers of) the model to optimally adapt to new
tasks during transfer learning [1] [2] [3] .
FinetuningScheduler orchestrates the gradual unfreezing
of models via a fine-tuning schedule that is either implicitly generated (the default) or explicitly provided by the user
(more computationally efficient). fine-tuning phase transitions are driven by
FTSEarlyStopping criteria (a multi-phase
extension of EarlyStopping),
user-specified epoch transitions or a composition of the two (the default mode). A
FinetuningScheduler training session completes when the
final phase of the schedule has its stopping criteria met. See
Early Stopping for more details on that callback’s configuration.
Basic Usage¶
If no fine-tuning schedule is user-provided, FinetuningScheduler will generate a
default schedule and proceed to fine-tune
according to the generated schedule, using default
FTSEarlyStopping
and FTSCheckpoint callbacks with
monitor=val_loss.
import lightning as L
from finetuning_scheduler import FinetuningScheduler
trainer = L.Trainer(callbacks=[FinetuningScheduler()])
Note
If not provided, FTS will instantiate its callback dependencies
(FTSEarlyStopping and
FTSCheckpoint) with default configurations and monitor=val_loss.
If the user provides base versions of these dependencies (e.g.
EarlyStopping,
ModelCheckpoint) the provided configuration of
those callbacks will be used to instantiate their FTS analogs instead.
The Default Fine-Tuning Schedule¶
Schedule definition is facilitated via
gen_ft_schedule() which dumps
a default fine-tuning schedule (by default using a naive, 2-parameters per level heuristic) which can be adjusted as
desired by the user and/or subsequently passed to the callback. Using the default/implicitly generated schedule will
often be less computationally efficient than a user-defined fine-tuning schedule but can often serve as a
good baseline for subsequent explicit schedule refinement and will marginally outperform many explicit schedules.
Specifying a Fine-Tuning Schedule¶
To specify a fine-tuning schedule, it’s convenient to first generate the default schedule and then alter the
thawed/unfrozen parameter groups associated with each fine-tuning phase as desired. Fine-tuning phases are zero-indexed
and executed in ascending order. In addition to being zero-indexed, fine-tuning phase keys should be contiguous and
either integers or convertible to integers via int().
First, generate the default schedule (output to
log_dir, defaults toTrainer.log_dir). It will be named after yourLightningModulesubclass with the suffix_ft_schedule.yaml.
import lightning as L
from finetuning_scheduler import FinetuningScheduler
trainer = L.Trainer(callbacks=[FinetuningScheduler(gen_ft_sched_only=True)])
Alter the schedule as desired.
Changing the generated schedule for this boring model…
1 0:
2 params:
3 - layer.3.bias
4 - layer.3.weight
5 1:
6 params:
7 - layer.2.bias
8 - layer.2.weight
9 2:
10 params:
11 - layer.1.bias
12 - layer.1.weight
13 3:
14 params:
15 - layer.0.bias
16 - layer.0.weight
… to have three fine-tuning phases instead of four:
1 0:
2 params:
3 - layer.3.bias
4 - layer.3.weight
5 1:
6 params:
7 - layer.2.*
8 - layer.1.bias
9 - layer.1.weight
10 2:
11 params:
12 - layer.0.*
Once the fine-tuning schedule has been altered as desired, pass it to
FinetuningSchedulerto commence scheduled training:
import lightning as L
from finetuning_scheduler import FinetuningScheduler
trainer = L.Trainer(callbacks=[FinetuningScheduler(ft_schedule="/path/to/my/schedule/my_schedule.yaml")])
Note
For each fine-tuning phase, FinetuningScheduler will unfreeze/freeze parameters
as directed in the explicitly specified or implicitly generated schedule. Prior to beginning the first phase of
training (phase 0), FinetuningScheduler will inspect the optimizer to determine if the user has manually
initialized the optimizer with parameters that are non-trainable or otherwise altered the parameter trainability
states from that expected of the configured phase 0. By default, FTS ensures the optimizer configured in
configure_optimizers will optimize the parameters (and only those parameters) scheduled to be optimized in phase
0 of the current fine-tuning schedule. This auto-configuration can be disabled if desired by setting
enforce_phase0_params to False.
Note
When freezing torch.nn.modules.batchnorm._BatchNorm modules, Lightning by default disables
BatchNorm.track_running_stats. Beginning with FTS 2.4.0, FTS overrides this behavior by default so that
even frozen BatchNorm layers continue to have track_running_stats set to True. To disable
BatchNorm.track_running_stats when freezing torch.nn.modules.batchnorm._BatchNorm modules, one can set the
FTS parameter frozen_bn_track_running_stats to False.
EarlyStopping and Epoch-Driven Phase Transition Criteria¶
By default, FTSEarlyStopping and epoch-driven
transition criteria are composed. If a max_transition_epoch is specified for a given phase, the next finetuning
phase will begin at that epoch unless
FTSEarlyStopping criteria are met first.
If epoch_transitions_only is
True, FTSEarlyStopping will not be used
and transitions will be exclusively epoch-driven.
Tip
Use of regex expressions can be convenient for specifying more complex schedules. Also, a per-phase
base_max_lr can be specified:
1 0:
2 params: # the parameters for each phase definition can be fully specified
3 - model.classifier.bias
4 - model.classifier.weight
5 max_transition_epoch: 3
6 1:
7 params: # or specified via a regex
8 - model.albert.pooler.*
9 2:
10 params:
11 - model.albert.encoder.*.ffn_output.*
12 max_transition_epoch: 9
13 lr: 1e-06 # per-phase maximum learning rates can be specified
14 3:
15 params: # both approaches to parameter specification can be used in the same phase
16 - model.albert.encoder.*.(ffn\.|attention|full*).*
17 - model.albert.encoder.embedding_hidden_mapping_in.bias
18 - model.albert.encoder.embedding_hidden_mapping_in.weight
19 - model.albert.embeddings.*
For a practical end-to-end example of using
FinetuningScheduler in implicit versus explicit modes,
see scheduled fine-tuning for SuperGLUE below or the
notebook-based tutorial.
Resuming Scheduled Fine-Tuning Training Sessions¶
Resumption of scheduled fine-tuning training is identical to the continuation of
other training sessions with the caveat that the provided checkpoint must
have been saved by a FinetuningScheduler session.
FinetuningScheduler uses
FTSCheckpoint (an extension of
ModelCheckpoint) to maintain schedule state with
special metadata.
import lightning as L
from finetuning_scheduler import FinetuningScheduler
trainer = L.Trainer(callbacks=[FinetuningScheduler()])
trainer.ckpt_path = "some/path/to/my_checkpoint.ckpt"
trainer.fit(...)
Training will resume at the depth/level of the provided checkpoint according the specified schedule. Schedules can be altered between training sessions but schedule compatibility is left to the user for maximal flexibility. If executing a user-defined schedule, typically the same schedule should be provided for the original and resumed training sessions.
Tip
By default (
restore_best is True),
FinetuningScheduler will attempt to restore
the best available checkpoint before fine-tuning depth transitions.
trainer = Trainer(callbacks=[FinetuningScheduler()])
trainer.ckpt_path = "some/path/to/my_kth_best_checkpoint.ckpt"
trainer.fit(...)
Note that similar to the behavior of
ModelCheckpoint, when resuming training
with a different FTSCheckpoint dirpath from the provided
checkpoint, the new training session’s checkpoint state will be re-initialized at the resumption depth with the
provided checkpoint being set as the best checkpoint.
Fine-Tuning All The Way Down!¶
There are plenty of options for customizing
FinetuningScheduler’s behavior, see
scheduled fine-tuning for SuperGLUE below for examples of composing different
configurations.
Note
Currently, FinetuningScheduler supports the following distributed strategies:
|
|
Note
FinetuningScheduler supports reinitializing all PyTorch optimizers (or subclasses
thereof) provided in torch.optim in the context of all
supported training strategies (including FSDP). Use of
ZeroRedundancyOptimizer is also supported, but currently only
outside the context of optimizer reinitialization.
Tip
Custom or officially unsupported strategies and lr schedulers can be used by setting
allow_untested to True.
Some officially unsupported strategies may work unaltered and are only unsupported due to
the Fine-Tuning Scheduler project’s lack of CI/testing resources for that strategy (e.g. single_tpu). Most
unsupported strategies and schedulers, however, are currently unsupported because they require varying degrees of
modification to be compatible.
For instance, with respect to strategies, deepspeed will require a
StrategyAdapter similar to the one written for FSDP
(FSDPStrategyAdapter) to be written before support can be added,
while tpu_spawn would require an override of the current broadcast method to include python objects.
Regarding lr schedulers, ChainedScheduler and
SequentialLR are examples of schedulers not currently supported
due to the configuration complexity and semantic conflicts supporting them would introduce. If a supported torch lr
scheduler does not meet your requirements, one can always subclass a supported lr scheduler and modify it as
required (e.g. LambdaLR is especially useful for this). PRs are
also always welcome!
Example: Scheduled Fine-Tuning For SuperGLUE¶
A demonstration of the scheduled fine-tuning callback
FinetuningScheduler using the
RTE and
BoolQ tasks of the
SuperGLUE benchmark and the
LightningCLI is available under ./fts_examples.
Since this CLI-based example requires a few additional packages (e.g. transformers, sentencepiece), you
should install them using the [examples] extra:
uv pip install finetuning-scheduler['examples']
There are three different demo schedule configurations composed with shared defaults (./config/fts_defaults.yaml) provided for the default ‘rte’ task. Note DDP (with auto-selected GPUs) is the default configuration so ensure you adjust the configuration files referenced below as desired for other configurations.
Note there will likely be minor variations in training paths and performance as packages (e.g. transformers,
datasets, finetuning-scheduler itself etc.) evolve. The precise package versions and salient environmental
configuration used in the building of this tutorial is available in the logs and checkpoints referenced below if you’re
interested.
# Generate a baseline without scheduled fine-tuning enabled:
python fts_superglue.py fit --config config/nofts_baseline.yaml
# Train with the default fine-tuning schedule:
python fts_superglue.py fit --config config/fts_implicit.yaml
# Train with a non-default fine-tuning schedule:
python fts_superglue.py fit --config config/fts_explicit.yaml
All three training scenarios use identical configurations with the exception of the provided fine-tuning schedule. See
the table below for a characterization of the relative computational and performance tradeoffs associated with these
FinetuningScheduler configurations.
FinetuningScheduler expands the space of possible
fine-tuning schedules and the composition of more sophisticated schedules can yield marginal fine-tuning performance
gains. That stated, it should be emphasized the primary utility of
FinetuningScheduler is to grant greater fine-tuning
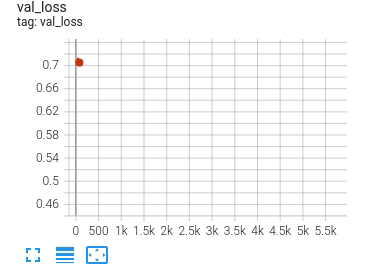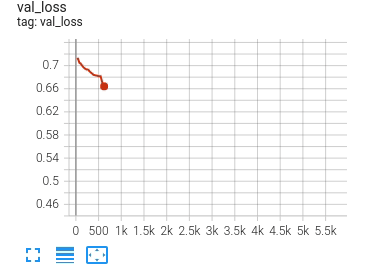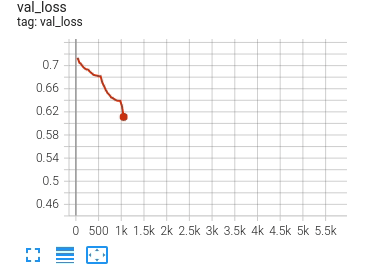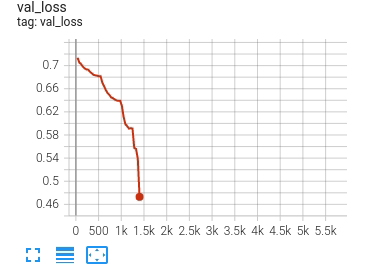
flexibility for model exploration in research. For example, glancing at DeBERTa-v3’s implicit training run, a critical
tuning transition point is immediately apparent:
Our val_loss begins a precipitous decline at step 3119 which corresponds to phase 17 in the schedule. Referring to our
schedule, in phase 17 we’re beginning tuning the attention parameters of our 10th encoder layer (of 11). Interesting!
Though beyond the scope of this documentation, it might be worth investigating these dynamics further and
FinetuningScheduler allows one to do just that quite
easily.
Full logs/schedules for all three scenarios are available as well as the checkpoints produced in the scenarios (caution, ~3.5GB).
Example Scenario
|
nofts_baseline
|
fts_implicit
|
fts_explicit
|
|---|---|---|---|
Fine-Tuning Schedule
|
None |
Default |
User-defined |
RTE Accuracy
(
0.81, 0.84, 0.85) |
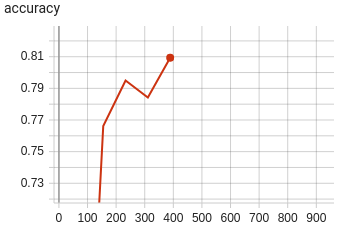
|
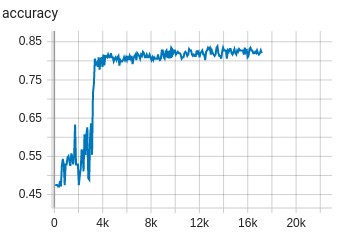
|
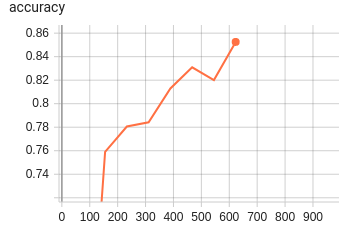
|
Note that though this example is intended to capture a common usage scenario, substantial variation is expected among
use cases and models. In summary, FinetuningScheduler
provides increased fine-tuning flexibility that can be useful in a variety of contexts from exploring model tuning
behavior to maximizing performance.
Footnotes¶
See also
