Optimizer Reinitialization¶
Overview¶
FinetuningScheduler (FTS) supports the initialization of new optimizers according to
a user-specified fine-tuning schedule. Similarly motivated to Fine-Tuning Scheduler’s
lr scheduler reinitialization feature, one can initialize new optimizers (or reinitialize
an existing one) at the beginning of one or more scheduled training phases.
Optimizer reinitialization is supported:
In both explicit and implicit fine-tuning schedule modes (see the Fine-Tuning Scheduler intro for more on basic usage modes)
With or without concurrent lr scheduler reinitialization
In the context of all supported training strategies (including FSDP)
With FTS >=
2.0.2
We’ll cover both implicit and explicit configuration modes below and provide a slightly altered version of the lr scheduler reinitialization example that demonstrates concurrent reinitialization of optimizers and lr schedulers at different phases.
Specifying Optimizer Configurations For Specific Fine-Tuning Phases¶
When defining a fine-tuning schedule (see the intro for basic schedule specification), a new
optimizer configuration can be applied to the existing training session at the beginning of a given phase by specifying
the desired configuration in the new_optimizer key. The new_optimizer dictionary format is described in the
annotated yaml schedule below and can be explored using the advanced usage example.
When specifying an optimizer configuration for a given phase, the new_optimizer dictionary requires at minimum
an optimizer_init dictionary containing a class_path key indicating the class of the optimizer
(list of supported optimizers) to be instantiated.
Any arguments with which you would like to initialize the specified optimizer should be specified in the
init_args key of the optimizer_init dictionary.
1 0:
2 params:
3 - model.classifier.bias
4 - model.classifier.weight
5 1:
6 params:
7 - model.pooler.dense.bias
8 - model.pooler.dense.weight
9 - model.deberta.encoder.LayerNorm.bias
10 - model.deberta.encoder.LayerNorm.weight
11 new_optimizer:
12 optimizer_init:
13 class_path: torch.optim.SGD
14 init_args:
15 lr: 2.0e-03
16 momentum: 0.9
17 weight_decay: 2.0e-06
18 ...
Optionally, one can also provide an lr scheduler reinitialization directive in the same phase as an optimizer
reinitialization directive. If one does not provide a new_lr_scheduler directive, the latest lr state will still be
restored and wrapped around the new optimizer prior to the execution of the new phase (as with lr scheduler
reinitialization):
1 0:
2 ...
3 1:
4 params:
5 - model.pooler.dense.bias
6 ...
7 new_optimizer:
8 optimizer_init:
9 class_path: torch.optim.SGD
10 init_args:
11 lr: 2.0e-03
12 momentum: 0.9
13 weight_decay: 2.0e-06
14 new_lr_scheduler:
15 lr_scheduler_init:
16 class_path: torch.optim.lr_scheduler.StepLR
17 init_args:
18 ...
19 pl_lrs_cfg:
20 ...
21 init_pg_lrs: [2.0e-06, 2.0e-06]
All optimizer reinitialization configurations specified in the fine-tuning schedule will have their configurations sanity-checked prior to training initiation.
Note
When reinitializing optimizers, FTS does not fully simulate/evaluate all compatibility scenarios so it is the user’s
responsibility to ensure compatibility between optimizer instantiations or to set
restore_best to False. For example consider the
following training scenario:
Phase 0: SGD training
Phase 1: Reinitialize the optimizer and continue training with an Adam optimizer
Phase 2: Restore best checkpoint from phase 0 (w/ `restore_best` default of `True`)
Phase 2 would fail due to incompatibility between Adam and SGD optimizer states. This issue could be avoided by
either reinitializing the Adam optimizer again in phase 2 or setting
restore_best` to False. [1]
Both lr scheduler and optimizer reinitialization configurations are only supported for phases >= 1. This is because
for fine-tuning phase 0, training component configurations will be the ones the user initiated the training
session with, usually via the configure_optimizer method of
LightningModule.
As you can observe in the explicit mode optimizer reinitialization example below, optimizers specified in different fine-tuning phases can be of differing types.
1 0:
2 params:
3 - model.classifier.bias
4 - model.classifier.weight
5 1:
6 params:
7 - model.pooler.dense.bias
8 - model.pooler.dense.weight
9 - model.deberta.encoder.LayerNorm.bias
10 - model.deberta.encoder.LayerNorm.weight
11 new_optimizer:
12 optimizer_init:
13 class_path: torch.optim.SGD
14 init_args:
15 lr: 2.0e-03
16 momentum: 0.9
17 weight_decay: 2.0e-06
18 ...
19 2:
20 params:
21 - model.deberta.encoder.rel_embeddings.weight
22 - model.deberta.encoder.layer.{0,11}.(output|attention|intermediate).*
23 - model.deberta.embeddings.LayerNorm.bias
24 - model.deberta.embeddings.LayerNorm.weight
25 new_optimizer:
26 optimizer_init:
27 class_path: torch.optim.AdamW
28 init_args:
29 weight_decay: 1.0e-05
30 eps: 1.0e-07
31 lr: 1.0e-05
32 ...
Once a new optimizer is re-initialized, it will continue to be used for subsequent phases unless replaced with another optimizer configuration defined in a subsequent schedule phase.
Optimizer Reinitialization With Generated (Implicit Mode) Fine-Tuning Schedules¶
One can also specify optimizer reinitialization in the context of implicit mode fine-tuning schedules. Since the
fine-tuning schedule is automatically generated, the same optimizer configuration will be applied at each of the
phase transitions. In implicit mode, the optimizer reconfiguration should be supplied to the
reinit_optim_cfg parameter of
FinetuningScheduler.
For example, configuring this dictionary via the LightningCLI, one
could use:
1 model:
2 ...
3 trainer:
4 callbacks:
5 - class_path: finetuning_scheduler.FinetuningScheduler
6 init_args:
7 reinit_optim_cfg:
8 optimizer_init:
9 class_path: torch.optim.AdamW
10 init_args:
11 weight_decay: 1.0e-05
12 eps: 1.0e-07
13 lr: 1.0e-05
14 reinit_lr_cfg:
15 lr_scheduler_init:
16 class_path: torch.optim.lr_scheduler.StepLR
17 ...
Note that an initial optimizer configuration should also still be provided per usual (again, typically via the
configure_optimizer method of LightningModule) and the initial
optimizer configuration can differ in optimizer type and configuration from the configuration specified in
reinit_optim_cfg applied at each phase transition. As with
explicit mode, concurrent reinit_lr_cfg configurations can
also be specified in implicit mode.
Advanced Usage Examples: Explicit and Implicit Mode Concurrent Optimizer and LR Scheduler Reinitialization¶
Demonstration optimizer and concurrent lr scheduler reinitialization configurations for both explicit and
fine-tuning scheduling contexts are available under ./fts_examples/config/advanced/reinit_optim_lr.
The concurrent optimizer and lr scheduler reinitialization examples use the same code and have the same dependencies as
the lr scheduler reinitialization-only (with the exception of requiring FTS >= 2.0.2 )
examples.
The two different demo schedule configurations are composed with shared defaults (./config/fts_defaults.yaml).
# Demo concurrent optimizer and lr scheduler reinitializations...
cd ./fts_examples
# with an explicitly defined fine-tuning schedule:
python fts_superglue.py fit --config config/advanced/reinit_optim_lr/fts_explicit_reinit_optim_lr.yaml
# with an implicitly defined fine-tuning schedule:
python fts_superglue.py fit --config config/advanced/reinit_optim_lr/fts_implicit_reinit_optim_lr.yaml
# with non-default `use_current_optimizer_pg_lrs` mode (and an implicit schedule):
python fts_superglue.py fit --config config/advanced/reinit_optim_lr/fts_implicit_reinit_optim_lr_use_curr.yaml
Similar to the explicitly defined lr reinitialization-only schedule example, we are using three distinct lr schedulers for three different training phases. In this case, there are also distinctly configured optimizers being used:
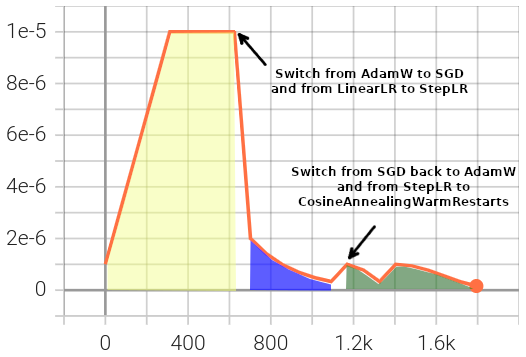
The configured phase 0 in yellow uses an
AdamWoptimizer andLinearLRscheduler with the initial lr and optimizer defined via the shared initial optimizer configuration.The configured phase 1 in blue uses a
SGDoptimizer andStepLRscheduler, including the specified initial lr for the existing parameter groups (2.0e-06).The configured phase 2 in green switches back to an
AdamWoptimizer but uses aCosineAnnealingWarmRestartsscheduler, with an assigned initial lr for each of the parameter groups.
Because we turned on DEBUG-level logging to trace reinitializations, we observe the following in our training log upon
the phase 1 optimizer reinitialization:
1Epoch 8: 100%|██████████| 78/78 ...
2...
3Fine-Tuning Scheduler has reinitialized the optimizer as directed:
4Previous optimizer state: AdamW
5... (followed by parameter group config details)
6New optimizer state: SGD
7... (followed by parameter group initial config details, note existing lr state or user directives may subsequently override the `lr`s in this initial config)
In the implicitly defined schedule scenario, we begin using the AdamW optimizer
but the SGD optimizer and StepLR
lr scheduler are specified via reinit_optim_cfg and
reinit_lr_cfg respectively. Both training components are
reinitialized at each phase transition and applied to all optimizer parameter groups.
1 ...
2 - class_path: finetuning_scheduler.FinetuningScheduler
3 init_args:
4 # note, we're not going to see great performance due
5 # to the shallow depth, just demonstrating the lr scheduler
6 # reinitialization behavior in implicit mode
7 max_depth: 4
8 restore_best: false # disable restore_best for lr pattern clarity
9 logging_level: 10 # enable DEBUG logging to trace all reinitializations
10 reinit_optim_cfg:
11 optimizer_init:
12 class_path: torch.optim.SGD
13 init_args:
14 lr: 1.0e-05
15 momentum: 0.9
16 weight_decay: 1.0e-06
17 reinit_lr_cfg:
18 lr_scheduler_init:
19 class_path: torch.optim.lr_scheduler.StepLR
20 init_args:
21 step_size: 1
22 gamma: 0.7
23 pl_lrs_cfg:
24 interval: epoch
25 frequency: 1
26 name: Implicit_Reinit_LR_Scheduler
27 # non-default behavior set in `fts_implicit_reinit_optim_lr_use_curr.yaml`
28 use_current_optimizer_pg_lrs: true
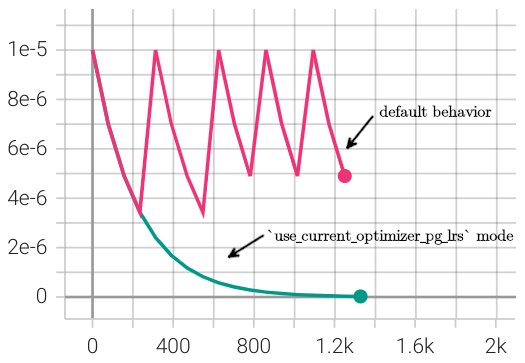
LR log for parameter group 1 reflecting repeated reinitialization of the SGD optimizer and StepLR lr scheduler (initial target lr = 1.0e-05) at each phase transition.
The behavioral impact of use_current_optimizer_pg_lrs (line 28 above) on the lr scheduler reinitializations can be clearly observed.¶
Note that we have disabled restore_best in both examples for
clarity of lr patterns.
Note
Optimizer reinitialization with FinetuningScheduler is currently in beta.
Configuration Appendix¶
Effective phase 0 config defined in ./config/advanced/reinit_optim_lr/fts_explicit_reinit_optim_lr.yaml, applying defaults defined in ./config/fts_defaults.yaml ⏎
1...
2model:
3 class_path: fts_examples.fts_superglue.RteBoolqModule
4 init_args:
5 optimizer_init:
6 class_path: torch.optim.AdamW
7 init_args:
8 weight_decay: 1.0e-05
9 eps: 1.0e-07
10 lr: 1.0e-05
11 ...
12 lr_scheduler_init:
13 class_path: torch.optim.lr_scheduler.LinearLR
14 init_args:
15 start_factor: 0.1
16 total_iters: 4
17 pl_lrs_cfg:
18 interval: epoch
19 frequency: 1
20 name: Explicit_Reinit_LR_Scheduler
Phase 1 config, defined in our explicit schedule ./config/advanced/reinit_optim_lr/explicit_reinit_optim_lr.yaml ⏎
1...
21:
3 params:
4 - model.pooler.dense.bias
5 - model.pooler.dense.weight
6 - model.deberta.encoder.LayerNorm.bias
7 - model.deberta.encoder.LayerNorm.weight
8 new_optimizer:
9 optimizer_init:
10 class_path: torch.optim.SGD
11 init_args:
12 lr: 1.0e-05
13 momentum: 0.9
14 weight_decay: 1.0e-06
15 new_lr_scheduler:
16 lr_scheduler_init:
17 class_path: torch.optim.lr_scheduler.StepLR
18 init_args:
19 step_size: 1
20 gamma: 0.7
21 pl_lrs_cfg:
22 interval: epoch
23 frequency: 1
24 name: Explicit_Reinit_LR_Scheduler
25 init_pg_lrs: [2.0e-06, 2.0e-06]
Phase 2 config, like all non-zero phases, defined in our explicit schedule ./config/advanced/reinit_optim_lr/explicit_reinit_optim_lr.yaml ⏎
1...
22:
3 params:
4 - model.deberta.encoder.rel_embeddings.weight
5 - model.deberta.encoder.layer.{0,11}.(output|attention|intermediate).*
6 - model.deberta.embeddings.LayerNorm.bias
7 - model.deberta.embeddings.LayerNorm.weight
8 new_optimizer:
9 optimizer_init:
10 class_path: torch.optim.AdamW
11 init_args:
12 weight_decay: 1.0e-05
13 eps: 1.0e-07
14 lr: 1.0e-05
15 new_lr_scheduler:
16 lr_scheduler_init:
17 class_path: torch.optim.lr_scheduler.CosineAnnealingWarmRestarts
18 init_args:
19 T_0: 3
20 T_mult: 2
21 eta_min: 1.0e-07
22 pl_lrs_cfg:
23 interval: epoch
24 frequency: 1
25 name: Explicit_Reinit_LR_Scheduler
26 init_pg_lrs: [1.0e-06, 1.0e-06, 2.0e-06, 2.0e-06]
