LR Scheduler Reinitialization¶
Overview¶
In some contexts it can be useful to re-wrap your optimizer with new lr scheduler configurations at the beginning of one or more scheduled training phases. Among others, example use cases include:
implementing complex lr schedules along with multi-phase early-stopping
injecting new parameter group specific rates on a scheduled basis
programmatically exploring training behavioral dynamics with heterogenous schedulers and early-stopping
LR scheduler reinitialization is supported:
In both explicit and implicit fine-tuning schedule modes (see the Fine-Tuning Scheduler intro for more on basic usage modes)
With or without concurrent optimizer reinitialization (FTS >=
2.0.2)In the context of all supported training strategies (including FSDP).
With FTS >=
0.1.4
As lr scheduler reinitialization is likely to be applied most frequently in the context of explicitly defined fine-tuning schedules, we’ll cover configuration in that mode first. Please see the optimizer reinitialization feature introduction for a review of concurrent optimizer and lr scheduler reinitialization.
Specifying LR Scheduler Configurations For Specific Fine-Tuning Phases¶
When defining a fine-tuning schedule (see the intro for basic schedule specification), a new
lr scheduler configuration can be applied to the existing optimizer at the beginning of a given phase by specifying the
desired configuration in the new_lr_scheduler key. The new_lr_scheduler dictionary format is described in the
annotated yaml schedule below and can be explored using the
advanced usage example.
When specifying an lr scheduler configuration for a given phase, the new_lr_scheduler dictionary requires at minimum
an lr_scheduler_init dictionary containing a class_path key indicating the class of the lr scheduler
(list of supported schedulers) to be instantiated and wrapped around your optimizer.
Any arguments you would like to pass to initialize the specified lr scheduler with should be specified in the
init_args key of the lr_scheduler_init dictionary.
1 0:
2 params:
3 - model.classifier.bias
4 - model.classifier.weight
5 1:
6 params:
7 - model.pooler.dense.bias
8 - model.pooler.dense.weight
9 - model.deberta.encoder.LayerNorm.bias
10 - model.deberta.encoder.LayerNorm.weight
11 new_lr_scheduler:
12 lr_scheduler_init:
13 class_path: torch.optim.lr_scheduler.StepLR
14 init_args:
15 step_size: 1
16 gamma: 0.7
17 ...
Optionally, one can include arguments to pass to Lightning’s lr scheduler configuration
(LRSchedulerConfig) in the pl_lrs_cfg dictionary.
1 0:
2 ...
3 1:
4 params:
5 - model.pooler.dense.bias
6 ...
7 new_lr_scheduler:
8 lr_scheduler_init:
9 class_path: torch.optim.lr_scheduler.StepLR
10 init_args:
11 step_size: 1
12 ...
13 pl_lrs_cfg:
14 interval: epoch
15 frequency: 1
16 name: Explicit_Reinit_LR_Scheduler
If desired, one can also specify new initial learning rates to use for each of the existing parameter groups in the
optimizer being wrapped via a list in the init_pg_lrs key.
1 ...
2 1:
3 params:
4 ...
5 new_lr_scheduler:
6 lr_scheduler_init:
7 ...
8 init_pg_lrs: [2.0e-06, 2.0e-06]
Note
It is currently is up to the user to ensure the number of parameter groups listed in init_pg_lrs matches the
number of optimizer parameter groups created in previous phases (and if using
ReduceLROnPlateau with a list of min_lr s, the
current number parameter groups). This number of groups is dependent on a number of
factors including the no_decay mapping of parameters specified in previous phases and isn’t yet
introspected/simulated in the current FinetuningScheduler version.
Finally, when reinitializing an lr scheduler for a given phase, one can direct FTS to use the current optimizer parameter group lr s rather
than defaulting to the existing optimizer’s initial_lr configuration for existing parameter groups. This mode is
enabled by setting the use_current_optimizer_pg_lrs key to True. For a concrete example of this behavior, see this example.
The init_pg_lrs key takes precedence over the use_current_optimizer_pg_lrs key if both are present. [1]
1 ...
2 1:
3 params:
4 ...
5 new_lr_scheduler:
6 lr_scheduler_init:
7 ...
8 use_current_optimizer_pg_lrs: true
All lr scheduler reinitialization configurations specified in the fine-tuning schedule will have their configurations sanity-checked prior to training initiation.
Note that specifying lr scheduler reinitialization configurations is only supported for phases >= 1. This is because
for fine-tuning phase 0, the lr scheduler configuration will be the scheduler that you initiate your training
session with, usually via the configure_optimizer method of
LightningModule.
Tip
If you want your learning rates logged on the same graph for each of the scheduler configurations defined in various phases, ensure that you provide the same name in the lr_scheduler configuration for each of the defined lr schedulers. For instance, in the lr scheduler reinitialization example, we provide:
1 model:
2 class_path: fts_examples.fts_superglue.RteBoolqModule
3 init_args:
4 lr_scheduler_init:
5 class_path: torch.optim.lr_scheduler.LinearLR
6 init_args:
7 start_factor: 0.1
8 total_iters: 4
9 pl_lrs_cfg:
10 # use the same name for your initial lr scheduler
11 # configuration and your ``new_lr_scheduler`` configs
12 # if you want LearningRateMonitor to generate a single graph
13 name: Explicit_Reinit_LR_Scheduler
As you can observe in the explicit mode lr scheduler reinitialization example below, lr schedulers specified in different fine-tuning phases can be of differing types.
1 0:
2 params:
3 - model.classifier.bias
4 - model.classifier.weight
5 1:
6 params:
7 - model.pooler.dense.bias
8 - model.pooler.dense.weight
9 - model.deberta.encoder.LayerNorm.bias
10 - model.deberta.encoder.LayerNorm.weight
11 new_lr_scheduler:
12 lr_scheduler_init:
13 class_path: torch.optim.lr_scheduler.StepLR
14 init_args:
15 step_size: 1
16 gamma: 0.7
17 pl_lrs_cfg:
18 interval: epoch
19 frequency: 1
20 name: Explicit_Reinit_LR_Scheduler
21 init_pg_lrs: [2.0e-06, 2.0e-06]
22 2:
23 params:
24 - model.deberta.encoder.rel_embeddings.weight
25 - model.deberta.encoder.layer.{0,11}.(output|attention|intermediate).*
26 - model.deberta.embeddings.LayerNorm.bias
27 - model.deberta.embeddings.LayerNorm.weight
28 new_lr_scheduler:
29 lr_scheduler_init:
30 class_path: torch.optim.lr_scheduler.CosineAnnealingWarmRestarts
31 init_args:
32 T_0: 3
33 T_mult: 2
34 eta_min: 1.0e-07
35 pl_lrs_cfg:
36 interval: epoch
37 frequency: 1
38 name: Explicit_Reinit_LR_Scheduler
39 init_pg_lrs: [1.0e-06, 1.0e-06, 2.0e-06, 2.0e-06]
Once a new lr scheduler is re-initialized, it will continue to be used for subsequent phases unless replaced with another lr scheduler configuration defined in a subsequent schedule phase.
Prior to the execution of each phase transition, the latest lr state [2] from the previous phase will be restored before proceeding with any lr scheduler reinitialization directive.
This is predominantly relevant only when training in restore_best mode or reinitializing the optimizer as well as lr scheduler.
Tip
If you have specified an lr scheduler with an lr_lambdas attribute in any phase,
(e.g. LambdaLR) you can have the last configured lambda
automatically applied to new groups in subsequent phases by setting the
apply_lambdas_new_pgs parameter to True. Note this
option will only affect phases without reinitialized lr schedulers. Phases with defined lr scheduler
reinitialization configs will always apply the specified config, including new lambdas if provided.
LR Scheduler Reinitialization With Generated (Implicit Mode) Fine-Tuning Schedules¶
One can also specify lr scheduler reinitialization in the context of implicit mode fine-tuning schedules. Since the
fine-tuning schedule is automatically generated, the same lr scheduler configuration will be applied at each of the
phase transitions. In implicit mode, the lr scheduler reconfiguration should be supplied to the
reinit_lr_cfg parameter of
FinetuningScheduler.
For example, configuring this dictionary via the LightningCLI, one
could use:
1 model:
2 class_path: fts_examples.fts_superglue.RteBoolqModule
3 init_args:
4 lr_scheduler_init:
5 class_path: torch.optim.lr_scheduler.StepLR
6 init_args:
7 step_size: 1
8 pl_lrs_cfg:
9 name: Implicit_Reinit_LR_Scheduler
10 trainer:
11 callbacks:
12 - class_path: finetuning_scheduler.FinetuningScheduler
13 init_args:
14 reinit_lr_cfg:
15 lr_scheduler_init:
16 class_path: torch.optim.lr_scheduler.StepLR
17 init_args:
18 step_size: 1
19 gamma: 0.7
20 pl_lrs_cfg:
21 interval: epoch
22 frequency: 1
23 name: Implicit_Reinit_LR_Scheduler
Note that an initial lr scheduler configuration should also still be provided per usual (again, typically via the
configure_optimizer method of LightningModule) and the initial
lr scheduler configuration can differ in lr scheduler type and configuration from the configuration specified in
reinit_lr_cfg applied at each phase transition. Because the
same schedule is applied at each phase transition, the init_pg_lrs list is not supported in an implicit fine-tuning
context.
Application of lr scheduler reinitialization in both explicit and implicit modes may be best understood via examples, so we’ll proceed to those next.
Advanced Usage Examples: Explicit and Implicit Mode LR Scheduler Reinitialization¶
Demonstration lr scheduler reinitialization configurations for both explicit and implicit fine-tuning scheduling contexts
are available under ./fts_examples/config/advanced/reinit_lr.
The lr scheduler reinitialization examples use the same code and have the same dependencies as the basic scheduled fine-tuning for SuperGLUE examples.
The two different demo schedule configurations are composed with shared defaults (./config/fts_defaults.yaml).
cd ./fts_examples
# Demo lr scheduler reinitialization with an explicitly defined fine-tuning schedule:
python fts_superglue.py fit --config config/advanced/reinit_lr/fts_explicit_reinit_lr.yaml
# Demo lr scheduler reinitialization with an implicitly defined fine-tuning schedule:
python fts_superglue.py fit --config config/advanced/reinit_lr/fts_implicit_reinit_lr.yaml
Notice in the explicitly defined schedule scenario, we are using three distinct lr schedulers for three different training phases:
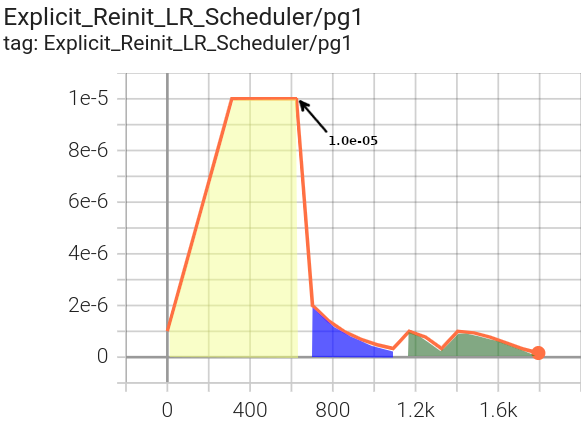
LR log for parameter group 1 (LinearLR initial target lr
= 1.0e-05)¶
Phase 0 in yellow (passed to our
LightningModule via the model
definition in our LightningCLI configuration) uses a
LinearLR scheduler (defined in
./config/advanced/reinit_lr/fts_explicit_reinit_lr.yaml) with the initial lr defined via the shared initial optimizer
configuration (defined in ./config/fts_defaults.yaml).
This is the effective phase 0 config (defined in ./config/advanced/reinit_lr/fts_explicit_reinit_lr.yaml, applying
defaults defined in ./config/fts_defaults.yaml):
1 model:
2 class_path: fts_examples.fts_superglue.RteBoolqModule
3 init_args:
4 optimizer_init:
5 class_path: torch.optim.AdamW
6 init_args:
7 weight_decay: 1.0e-05
8 eps: 1.0e-07
9 lr: 1.0e-05
10 ...
11 lr_scheduler_init:
12 class_path: torch.optim.lr_scheduler.LinearLR
13 init_args:
14 start_factor: 0.1
15 total_iters: 4
16 pl_lrs_cfg:
17 interval: epoch
18 frequency: 1
19 name: Explicit_Reinit_LR_Scheduler
Phase 1 in blue uses a StepLR scheduler, including the specified
initial lr for the existing parameter groups (2.0e-06).
pg1 starts at |
pg3 starts at the default of |
|---|---|
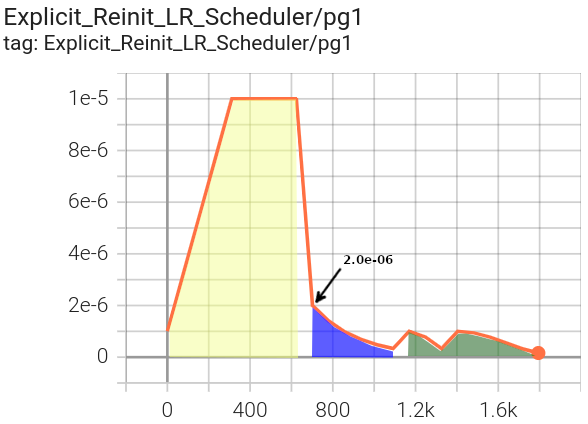
|
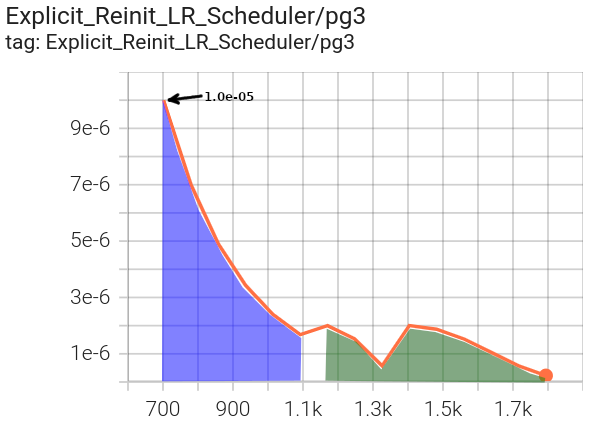
|
This is the phase 1 config (defined in our explicit schedule ./config/advanced/reinit_lr/explicit_reinit_lr.yaml):
1 ...
2 1:
3 params:
4 - model.pooler.dense.bias
5 - model.pooler.dense.weight
6 - model.deberta.encoder.LayerNorm.bias
7 - model.deberta.encoder.LayerNorm.weight
8 new_lr_scheduler:
9 lr_scheduler_init:
10 class_path: torch.optim.lr_scheduler.StepLR
11 init_args:
12 step_size: 1
13 gamma: 0.7
14 pl_lrs_cfg:
15 interval: epoch
16 frequency: 1
17 name: Explicit_Reinit_LR_Scheduler
18 init_pg_lrs: [2.0e-06, 2.0e-06]
Phase 2 in green uses a CosineAnnealingWarmRestarts scheduler, with
the assigned initial lr for each of the parameter groups (1.0e-06 for pg1 and 2.0e-06 for pg3).
pg1 oscillates between |
pg3 oscillates between |
|---|---|
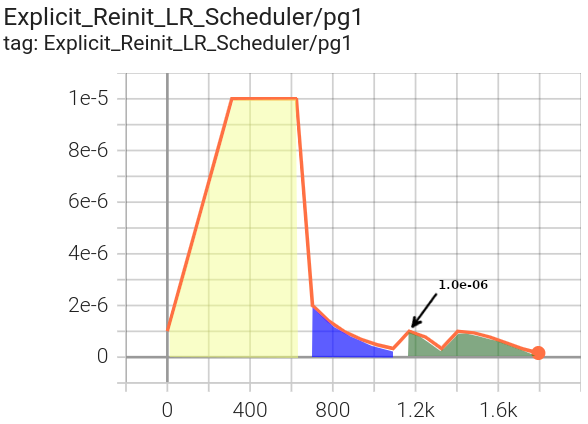
|
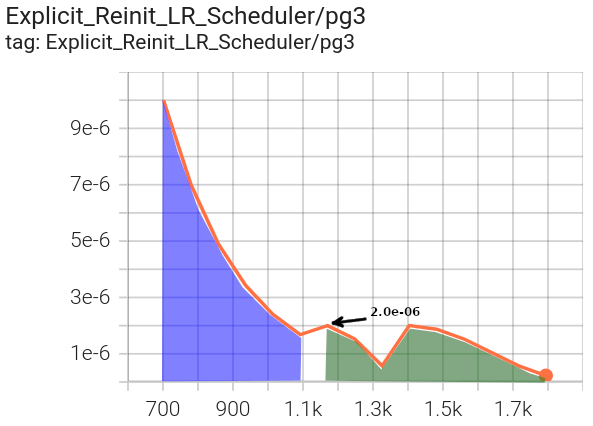
|
This is the phase 2 config (like all non-zero phases, defined in our explicit schedule
./config/advanced/reinit_lr/explicit_reinit_lr.yaml):
1 ...
2 2:
3 params:
4 - model.deberta.encoder.rel_embeddings.weight
5 - model.deberta.encoder.layer.{0,11}.(output|attention|intermediate).*
6 - model.deberta.embeddings.LayerNorm.bias
7 - model.deberta.embeddings.LayerNorm.weight
8 new_lr_scheduler:
9 lr_scheduler_init:
10 class_path: torch.optim.lr_scheduler.CosineAnnealingWarmRestarts
11 init_args:
12 T_0: 3
13 T_mult: 2
14 eta_min: 1.0e-07
15 pl_lrs_cfg:
16 interval: epoch
17 frequency: 1
18 name: Explicit_Reinit_LR_Scheduler
19 init_pg_lrs: [1.0e-06, 1.0e-06, 2.0e-06, 2.0e-06]
In the implicitly defined schedule scenario, the StepLR lr scheduler
specified via reinit_lr_cfg (which happens to be the same as
the initially defined lr scheduler in this case) is reinitialized at each phase transition and applied to all optimizer
parameter groups.
1 ...
2 - class_path: finetuning_scheduler.FinetuningScheduler
3 init_args:
4 # note, we're not going to see great performance due
5 # to the shallow depth, just demonstrating the lr scheduler
6 # reinitialization behavior in implicit mode
7 max_depth: 4
8 # disable restore_best for lr pattern clarity
9 restore_best: false
10 reinit_lr_cfg:
11 lr_scheduler_init:
12 class_path: torch.optim.lr_scheduler.StepLR
13 init_args:
14 step_size: 1
15 gamma: 0.7
16 pl_lrs_cfg:
17 interval: epoch
18 frequency: 1
19 name: Implicit_Reinit_LR_Scheduler
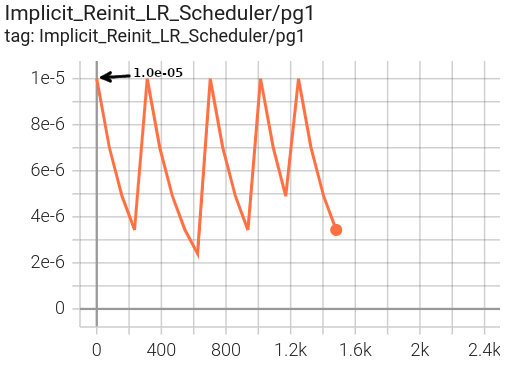
|
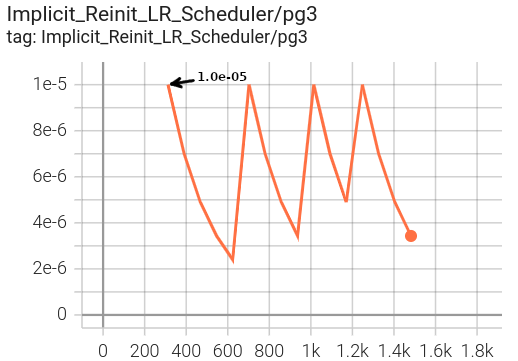
|
Note that we have disabled restore_best in both examples for
clarity of lr patterns.
